
작성자
- 이경훈(Speech AI Lab)
- AI를 활용한 가창 음성 합성 및 음악 생성 연구를 하고 있습니다.
이런 분이 읽으면 좋습니다!
- 프롬프트 기반의 음악 생성 연구의 배경이 궁금하신 분
- 프롬프트 기반의 음악 생성 모델의 최신 동향과 인사이트를 얻고 싶으신 분
이 글로 확인할 수 있는 내용
- 프롬프트 기반의 음악 생성 모델의 특징과 한계
안녕하세요. 엔씨에서 Music AI 연구를 하는 이경훈입니다.
엔씨 AI Center의 Speech AI Lab에서는 음성 인식, 음성 합성, 음악 생성 등과 같은 연구를 하고 있습니다. 그중 Music AI 팀은 가창 음성 합성 및 음악 생성 분야를 연구합니다.
이 글에서는, 엔씨 Music AI 팀이 주목하고 있는 프롬프트(Prompt) 기반의 최신 생성 모델에 대해서 알아보고, 사운드와 음악 생성 분야에서 어떻게 연구가 진행되고 있는지를 소개하고자 합니다.
먼저 “엔씨에서 음악 AI 기술을 왜 연구하게 되었는지”가 궁금하실 텐데요. Music AI 기술이 기여할 엔씨 게임의 미래를 설명해 드린 후, 본론으로 들어가도록 하겠습니다.
Music AI 팀의 연구 방향성
- AI 기술을 활용하여 음악 제작과 녹음에 필요한 비용 절감, 음악 전문가들이 창의적인 음악 작업에 더 힘을 쏟을 수 있도록 도움
- 유저 스스로 자신의 취향대로 만드는 게임테마, 더 몰입감 높은 게임으로 확장
엔씨의 Music AI팀은 음악에 AI 기술을 활용하기 위하여 크게 두 가지 방향성을 세웠습니다.
하나는, AI 기술을 이용하여 게임 제작 시 야기되는 반복적인 작업이나, 가수나 오케스트라를 섭외하기 위하여 들어가는 시간과 비용을 줄여 줌으로써, 엔씨 사운드 센터의 전문가분들이 창의적인 작업에 집중할 수 있도록 만들어주는 것입니다. 또 다른 하나로는 이 글의 주제인 프롬프트 기반의 음악 생성 기술입니다. 전문적인 지식 없이 자유로운 텍스트나 오디오를 기반으로 음악을 생성할 수 있다면, 게임 속에서 캐릭터의 외모를 커스터마이징하듯 자신만의 음악을 생성하여 자기 영지의 배경 음악으로 사용할 수도 있습니다. 혹은 게임 입장 시, 마을에서 매번 똑같은 BGM이 아니라 기존의 테마는 유지하면서, 날씨에 따라, 계절에 따라, 기념일에 따라 변화되는 BGM이 생성된다면 게임에 대한 몰입감이 커질 것입니다.
자, 그럼 이제 본론을 시작하겠습니다. 😊
1. 개요
생성형 AI 모델(generative AI models)은 기존에 없었던 새로운 것들을 만들어 내는 능력을 보여주면서 관심을 받아왔습니다. Vision 분야에서는 Open AI의 DALL-E2 1와 Stability AI의 stable diffusion이 입력으로 들어오는 텍스트 프롬프트의 내용을 바탕으로 사실적이고 창의적인 이미지를 생성할 수 있는 능력을 보여주었습니다. 특히, 창의성이 필요한 영역인 미술 대회와 국제 사진 대회에서 AI로 만들어진 그림이 수상을 하는 사례가 나타나면서 AI가 실제로 사람과 견주어도 구분하기 어려울 정도의 생성 능력을 갖추고 있음이 입증되고 있습니다[그림1, 그림2]. 자연어 분야에서는 ChatGPT가 생성형 언어 모델로 유명세를 떨쳤습니다. 물론, ChatGPT 이전에도 대규모 언어 모델들이 개발되어 왔습니다. 하지만, 챗봇의 형태로 사용자의 접근이 용이한 인터페이스를 제공함으로써, 마치 AI와 대화하듯 자연스럽게 언어 모델을 사용할 수 있었기 때문에 큰 관심을 불러일으킬 수 있었습니다. 이렇듯 생성형 AI 모델의 기술이 향상되고 사람과 대화하듯 프롬프트로 주고받는 인터페이스가 이목을 끌었다는 점에서, 우리는 프롬프트 기반의 생성 모델에 주목할 필요가 있습니다.
 그림 1. 생성형 AI 모델인 미드 저니로 생성된 “스페이스 오페라 극장”
Colorado State Fair Fine Arts Competition에서 “디지털 예술/디지털 이미지 사진” 부문 신인 아티스트 부문 1위 차지
출처 : https://www.seoul.co.kr/news/newsView.php?id=20220904500075
그림 1. 생성형 AI 모델인 미드 저니로 생성된 “스페이스 오페라 극장”
Colorado State Fair Fine Arts Competition에서 “디지털 예술/디지털 이미지 사진” 부문 신인 아티스트 부문 1위 차지
출처 : https://www.seoul.co.kr/news/newsView.php?id=20220904500075
 그림 2. 2023년 소니 월드 포토그래피 어워드에서 수상작으로 선정된 AI 사진
출처 : https://www.etnews.com/20230419000095
그림 2. 2023년 소니 월드 포토그래피 어워드에서 수상작으로 선정된 AI 사진
출처 : https://www.etnews.com/20230419000095
2. 프롬프트 기반 음성 생성 기술
오디오 생성 분야에서도 프롬프트 기반의 생성 모델을 제안하는 연구가 진행되고 있습니다. 오디오 생성 모델의 대표적인 분야로는 음성 합성(text-to-speech, TTS) 연구 분야가 있습니다. 기존의 TTS 모델의 경우 입력으로 들어오는 텍스트를 단순히 읽어주는 형태였습니다. 다른 사람의 목소리를 모방하여 음색을 변화시키거나, 음의 높이와 길이 등을 조절하거나, 감정에 따른 억양을 표현하는 등 여러 기능을 수행하기 위해서 별도의 모듈이 필요하거나 데이터셋에 수작업으로 태그를 일일이 달아주는 일이 필요하였습니다. 프롬프트 기반의 음성 합성 모델은 이러한 어려움을 스타일을 묘사한 텍스트 프롬프트를 입력으로 넣어주면서 해결하였습니다. PromptTTS 2와 InstructTTS 3는 발화의 타겟이 되는 텍스트를 콘텐트(content) 프롬프트로 명명하고 발화 스타일을 묘사한 텍스트를 스타일(style) 프롬프트로 구성하여 입력으로 넣어 줌으로써, 별도의 모듈없이 원하는 스타일의 음성을 생성할 수 있었습니다. VALL-E 4와 SpearTTS 5에서는 speech 데이터를 프롬프트로 활용하여 생성되는 음성의 음색과 스타일을 변환할 방법을 제안하였습니다. 특히, 해당 모델들은 기존의 TTS 분야에서 어려운 문제로 여겨지던 zero-shot 시나리오에서, 훈련 데이터 셋에 없는 3초 정도의 발화만으로도 해당 음성의 음색으로 다양한 발화를 만들어 낼 수 있었습니다.
3. 프롬프트 기반 오디오 생성 기술
음성뿐만 아니라 일반적인 모든 소리(sound)를 생성해 내는 연구도 진행되고 있습니다. Make-An-Audio 6과 AudioLDM 7은 diffusion 기반의 오디오 생성 모델로 동물 소리, 악기 소리, 환경음 등 다양한 소리를 텍스트 프롬프트로부터 생성할 수 있습니다. 자유로운 형식의 텍스트 프롬프트를 통하여 어떤 소리를 만들어 낼 것인지 선택할 수 있을 뿐만 아니라, 프롬프트에서 설명하고 있는 상황에 따라 소리를 생성할 수 있음을 보여주고 있습니다. 예를 들어 특정 작은 방에서 말하는 소리와 큰 홀에서 말하는 소리 반향의 차이를 프롬프트만으로 만들어 낼 수 있다는 것을 보여주었습니다. 이러한 프롬프트로 오디오를 생성하고 조절하는 기술은 또 다른 응용으로 이어지기도 합니다. 소설의 어떤 장소에 대한 분위기를 묘사하는 텍스트를 프롬프트로 넣어주면 BGM처럼 음악을 만들어 낼 수 있고, 이미지 캡셔닝(image captioning) 기술을 이용하여 이미지를 설명하는 텍스트를 만들어 생성 모델에 넣어주면 이미지에 어울리는 소리가 만들어질 수 있습니다. 이런 기술을 활용하면 기존의 소리가 없던 소설, 웹툰 등의 분야에 쉽고 빠르게 오디오를 생성하여 삽입함으로써 사용자에게 더욱 풍성한 콘텐트를 생성할 수 있다는 것을 예상할 수 있습니다. 이 밖에도 적은 데이터 셋과 모델을 이용하여 효율적으로 프롬프트 기반의 생성 모델을 만들기 위한 연구 8와 이미지, 소리, 동영상, 텍스트 등을 입출력으로 하는 멀티 모달(multi-modal) 생성 모델에 대한 연구 9도 진행이 되고 있습니다.
4. 프롬프트 기반 음악 생성 기술
자동 음악 생성에 대한 연구는 딥러닝 이전부터 현재에 이르기까지 활발하게 이루어져 왔습니다. 10 음악을 생성하기 위하여 악보, MIDI, waveform 과 같은 다양한 format이 사용되었고, 생성하고자 하는 음악의 구조적 특징을 표현하기 위하여 음악 정보를 토대로 문맥적 의미를 담은 새로운 feature를 만들어 사용하는 연구도 있습니다. 음악 생성 연구 분야로는 1) mono/polyphony generation, 2) multi-track/multi-instrument generation, 3) chord conditioned melody generation, 4) melody harmonization, 5) track-conditional generation 등이 있습니다. 선행 연구들이 사용한 데이터 format과 task가 다양한 것은 음악을 하나의 정형화된 구조로 분석하기가 어렵고, 현대 음악으로 오면서 음악을 이루는 구성 요소들이 복잡하게 얽혀 있기 때문입니다. 음악성(musicality)을 유지하면서 기존과 다른 참신함(novelty)을 가진 샘플을 생성하기 위해서는 고품질의 데이터셋을 구축하고 데이터로부터 수직/수평적인 구조적 특징을 파악하기 위한 모델을 구축하는 등 데이터셋부터 모델까지 잘 디자인이 되어 있어야만 합니다.
 그림 3. 프롬프트 기반 음악 생성 모델 모식도
그림 3. 프롬프트 기반 음악 생성 모델 모식도
4-1. 선행 연구
프롬프트 기반의 음악 생성 모델은 음악을 이해하기 위한 전문적인 지식을 요구하지 않습니다(그림 3). 단지 다양한 장르와 악기로 이루어진 음악과 음악의 장르와 스타일 등을 묘사하는 대량의 (텍스트, 음악) 쌍의 데이터셋이 필요합니다. 음악을 하나의 문장으로 설명할 수 없다면 하나의 음악에 여러 개의 문장을 만들어 학습에 사용할 수도 있습니다. 한발 더 나아가서는, 딥러닝 모델을 이용한다면 이러한 대량의 데이터셋을 일일이 수집하지 않아도 됩니다. Noise2Music 11 에서는 거대 언어 모델 (large language model, LLM)을 이용하여 음악을 묘사하는 문장에 대한 후보 텍스트 데이터셋을 만들고, (텍스트, 음악) 쌍의 데이터셋으로 사전에 학습된 딥러닝 모델을 이용하여 음악에 어울리는 텍스트를 추려냅니다. 심지어 MusicLM 에서는 (텍스트, 음악) 쌍의 데이터셋을 만들 필요가 없이 음악 데이터셋 만을 이용하여 학습합니다. MusicLM 12은 오디오와 텍스트로부터 학습된 세 개의 모델이 만들어내는 representation token들을 사용합니다. Music LM의 transformer decoder 모듈들은 음악데이터셋 만을 이용하여 해당 token들을 단계적으로 예측하는 방식으로 학습됩니다. 프롬프트 기반의 음악 생성 모델들은 텍스트로 장르를 변화시키거나 생성되는 음악의 악기를 변화시킬 수도 있고, 음악과 음악의 중간에 빈 부분이 있다면 문맥을 고려하여 채워줄 수도 있습니다. 어떻게 하면 이런 프롬프트 기반의 음악 생성 모델을 만들 수 있을까요? 최근의 모델에서는 두 가지 방법론이 주로 사용되고 있습니다. DALL-E2, AudioLDM과같이 diffusion 기반의 모델들 11 13이 있고 AudioLM 14과 MusicLM 12 과 같이 LLM 모델들의 representation들을 이용하여 학습하는 방법론이 있습니다. 여기서 MusicLM에 대해 자세히 살펴보면서 프롬프트 기반의 음악 생성 모델이 어떻게 작동하는지 살펴보겠습니다.
4-2. MusicLM
4-2-1. 모델구조
MusicLM은 그림과 같이 세 개의 모델, SoundStream15, w2v-BERT16, 그리고 MuLan17 을 사용합니다. SoundStream은 음질을 최대한 유지한 채 오디오를 압축시키는 neural audio codec 모델이고, w2v-BERT는 masked-language-modeling(MLM) 방식으로 audio representation을 만들어주는 모델로, 두 모델 모두 오디오 데이터셋만을 이용하여 학습됩니다. MuLan은 (오디오, 텍스트) 쌍을 이용하여 유사한 의미를 가진 오디오와 텍스트가 임베딩 공간상에 가까운 거리에 위치하도록 학습된 모델입니다.
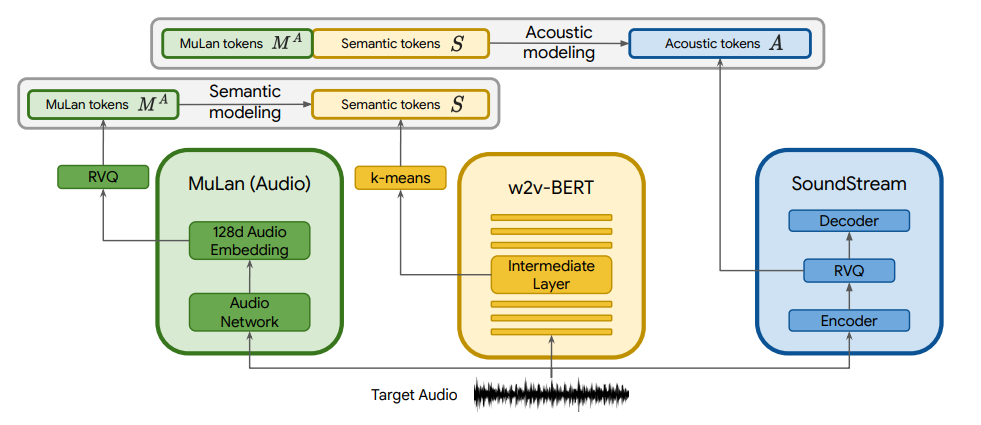 그림 4. MusicLM의 논문 그림 Training 시 flow
그림 4. MusicLM의 논문 그림 Training 시 flow
 그림 5. MusicLM의 논문 그림 Inference 시 flow
그림 5. MusicLM의 논문 그림 Inference 시 flow
MusicLM은 그림 4과 같이 SoundStream의 중간 feature를 acoustic token으로 w2v-BERT의 중간 feature를 semantic token으로 명명하여 사용합니다. 학습 시에는 MuLan audio token으로부터 semantic token을 예측하는 semantic modeling을 진행하고, MuLan audio token과 semantic token으로 coarse acoustic token을 만들고 coarse acoustic token으로부터 fine acoustic token을 만드는 acoustic modeling을 진행합니다. 최종적으로 Fine acoustic token은 SoundStream을 통하여 waveform으로 변환되어 생성됩니다. 각각의 모델링에서는 transformer decoder 기반의 autoregressive 모델들이 사용됩니다. 생성 시에는 그림 5와 같이 MuLan text token을 입력으로 하여 semantic token과 acoustic token을 순차적으로 예측하는 방식을 취합니다.
4-2-2. 데이터셋
MusicLM의 SoundStream과 w2v-BERT를 학습시키기 위해서 Free Music Archive (FMA) dataset을 사용하고, MuLan의 tokenizer와 semantic/acoustic modeling의 autoregressive model은 24kHz의 5백만개의 클립 (280K 시간)을 사용하여 학습합니다. MusicLM에서는 평가를 위한 새로운 데이터셋인 MusicCaps를 제안하고 있습니다(그림 6).
 그림 6. MusicCaps
그림 6. MusicCaps
MusicCaps는 AudioSet으로부터 5.5K 개의 음악 클립을 (텍스트, 오디오) 쌍으로 가지고 있습니다. text에는 장르, 분위기, 템포, 가수 음성, 악기, 리듬 등의 정보가 포함되어 있습니다. 장르에 대한 불균형 문제로 평가에 영향을 줄 수 있기 때문에 5.5K 클립에서 그림 7과 같이 장르가 균등하도록 1K 샘플을 따로 준비하여 평가하였습니다.
 그림 7. MusicCaps에서 모든 장르가 균등하도록 뽑은 샘플
그림 7. MusicCaps에서 모든 장르가 균등하도록 뽑은 샘플
4-2-3. 결과
프롬프트 기반의 음악 생성 모델을 평가하는 방법은 크게 두 가지로, 생성된 음악의 품질이 얼마나 좋은지, 주어진 프롬프트를 얼마나 잘 반영하여 음악이 만들어졌는지로 나눌 수 있습니다. MusicLM에서는 평가를 위한 metric으로 Fréchet Audio Distance(FAD), KL Divergence (KLD), MuLan Cycle Consistenc y (MCC) 로 3개의 metric을 사용하였습니다. FAD score가 낮은 샘플을 생성하는 모델이 더 실제와 유사한 오디오를 생성할 것으로 예상할 수 있고, 생성된 샘플의 KLD 가 낮을수록 실제 참조(reference) 음악과 음향적 특징이 비슷하다고 기대할 수 있습니다. MCC는 MusicCaps의 텍스트와 생성된 음악의 MuLan 임베딩을 각각 계산하고 두 임베딩 간의 코사인 유사도를 측정하는 값으로, 값이 클수록 해당 텍스트를 잘 반영하는 음악을 생성했다고 평가할 수 있습니다.
 표 1. MusicLM의 표
표 1. MusicLM의 표
MusicLM은 이전의 text-to-music model인 Riffusion과 MuBERT와 성능을 비교하였습니다. 표1에서처럼 FAD와 KLD의 경우 MusicLM이 두 개의 모델보다 낮은 값을 보임을 알 수 있고, MCC는 더 높은 것을 확인할 수 있습니다. 실제 사람이 들었을 때 어떤 샘플이 가장 나은지 테스트를 한 결과 MusicLM이 두 개의 샘플보다 더 선호되는 것을 확인할 수 있었지만, 실제 샘플과 비교했을 때는 아직 차이가 존재함을 확인할 수 있었습니다.
4-2-4. 활용방안
MusicLM은 프롬프트 기반의 음악 생성 모델이 단순히 텍스트로부터 음악을 만들어 주는 매커니즘 외에도 다양한 확장이 가능하다고 말하고 있습니다. MusicLM을 보면 텍스트로부터 얻어지는 정보(semantic token)와 오디오로부터 얻어지는 정보(acoustic token)을 나누어 생성하고 있습니다. 이러한 구조 덕분에 melody conditioning 방법으로 오디오 샘플로부터 멜로디를 추출하고 텍스트를 통하여 멜로디 속의 장르와 악기를 변화시키면서 음색을 바꾸는 것이 가능한 것을 보여주고 있습니다. 또한 이미 만들어진 음악을 이용하여 이후 이어질 음악을 만들어주는 story mode도 소개하고 있습니다. 이미지와 어울리는 음악을 생성하기 위하여, 자동 이미지 캡셔닝 모델로부터 이미지에 대한 설명을 텍스트로 만들어 MusicLM에 넣어주면 image-to-music 모델처럼 사용할 수도 있습니다. 이처럼 프롬프트 기반의 음악 생성 모델을 어떻게 구성하느냐에 따라서 활용도가 많아질 것으로 보입니다. 대량의 데이터를 기반으로 거대한 모델이 데이터 쌍들의 상관관계를 학습함으로써 만들어지는 데이터의 잠재적 표현 방식(latent representation)들을 이용하여 새로운 데이터에 적용하거나 새로운 응용 분야를 만들어 낼 수 있을 것으로 기대됩니다.
4-3. 현재 기술의 한계
프롬프트 기반의 음악 생성 모델은 텍스트로부터 다양한 음악을 만들어 낼 수 있다는 장점을 가지고 있지만, 실제로 현업의 전문가들이 사용하기에는 뚜렷한 한계를 보여주고 있습니다. 첫 번째로 음악이 무작위로 생성이 되기 때문에 원하는 결과를 얻기 위해서 반복적으로 합성을 해야 합니다. 텍스트에 포함된 장르, 악기 등을 토대로 만들어지기는 하지만 원하는 멜로디가 나오지 않을 경우 계속 반복해서 음악을 생성하여야 합니다. 두 번째로 음악을 표현하는 것이 어렵습니다. 장르, 악기 등 음악을 설명할 수 있는 키워드도 세부적으로 들어가면 다양하게 나누어질 수 있습니다. 여기에 코드, 템포 등과 같은 음악적인 요소와 레가토, 스타카토 등 연주법에 대한 내용, ‘우울하게, 밝게, 신나게’ 등 분위기에 대한 주관적인 표현 등 텍스트로 표현하는 것들이 다양하게 나올 수 있기 때문에, 훈련 데이터셋에서 정의된 표현 외에는 음악을 생성하기 어려워집니다. 세 번째로 텍스트로 생성되는 오디오의 미세 조정이 어렵습니다. 현업에서 음악을 만드는 경우 logic pro, cubase와 같은 DAW 툴을 이용하여 작업을 하게 되는데, 각 track에 대한 정보와 미디 정보 등이 제공되지 않기 때문에 하나하나의 음을 조정하거나 악기의 음색을 변화시키는 등 세부적인 작업을 수행하기 힘들게 됩니다. 마지막으로 학습에 사용하는 데이터셋과 생성되는 음악에 대한 저작권 관련 이슈가 있습니다. 만약에 훈련 데이터 셋을 구성할 때 저작권을 고려하지 않고 만들게 되는 경우 저작권에 위배되는 곡이 생성될 수 있습니다. MusicLM에서도 생성된 음악의 극히 일부가 훈련 데이터셋에서 나오는 경우가 있었고, 생성된 샘플의 1%가량의 생성물들이 훈련 데이터셋과 유사한 점이 있다는 것을 언급하였습니다. 만약 저작권에 이슈가 없는 데이터셋을 학습에 사용하였다고 하여도 생성되는 음악이 실제 있는 음악과 유사한 음악이 생성되지 않는다는 보장이 없습니다. 또한, 생성 AI가 만든 음악의 저작권을 인정할 수 있는지, 인정한다면 주체가 누구인지 등의 이슈가 존재합니다.
5. 엔씨에서의 음악 생성 기술
프롬프트를 이용한 음악 생성 기술을 이용하여 완성도가 높은 결과물을 만들어 내기는 어려운 일입니다. 데이터셋을 모을 때도, 음악을 생성할 때도 저작권과 같이 이슈가 항상 따라다닐거라고 생각합니다. 하지만 현재 프롬프트 기반의 생성 모델이 보여준 가능성처럼 음악 생성 분야에서도 고품질의 음악을 자유롭게 만들 수 있는 모델을 개발할 수 있으리라 생각합니다. 엔씨의 게임에서 음악은 중요한 역할을 하고 있습니다. 로그인 타이틀 화면에서 나오는 웅장한 음악과 각 마을의 분위기를 느끼게 해주는 테마 음악, 몬스터가 있는 필드와 던전에서의 배경 음악 등 다양한 곳에서 음악이 활용되고 있습니다. 그리고 엔씨의 사운드 센터는 오랜 시간 동안 이러한 게임 음악을 만들어왔기 때문에 많은 노하우와 리소스를 축적하고 있습니다. 저희 Music AI팀에서는 이제까지 보여온 엔씨의 음악적 역량과 AI 기술이 결합된다면 새로운 기술을 만들 수 있으리라 생각하고, 더불어 다른 게임 회사보다 엔씨가 가장 잘할 수 있으리라 생각합니다.
엔씨 Music AI 팀은 상상을 미래를 만들기 위하여 열심히 연구하고 있습니다. AI를 활용한 음악 생성 기술을 통해 어떤 새로운 즐거움을 만들어 볼 수 있을지 오늘도 고민 중입니다. 😊 Music AI팀의 연구에 언제나 관심과 기대를 부탁드리며, 이 글이 프롬프트로부터 음악을 생성하는 연구 분야에 관심 있으신 분들에게 조금이나마 도움이 되기를 바랍니다.
덧붙여, Music AI 팀의 연구와 연구 문화에 관심 있으신 분들은 엔씨블로그 글을 봐주시면 좋겠습니다. 긴 글 읽어 주셔서 감사합니다!
6. References
-
Hierarchical Text-Conditional Image Generation with CLIP Latents ↩
-
PromptTTS: Controllable Text-to-Speech with Text Descriptions ↩
-
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt ↩
-
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers ↩
-
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision ↩
-
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models ↩
-
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models ↩
-
Efficient Neural Music Generation ↩
-
Any-to-Any Generation via Composable Diffusion ↩
-
A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions ↩
-
Noise2Music: Text-conditioned Music Generation with Diffusion Models ↩ ↩2
-
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion ↩
-
AudioLM: a Language Modeling Approach to Audio Generation ↩
-
SoundStream: An End-to-End Neural Audio Codec ↩
-
W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training ↩
-
MuLan: A Joint Embedding of Music Audio and Natural Language ↩
