
- 인삿말
- 견고함(robustness)이 도대체 뭐야?
- 견고한 놈, 견고하지 않은 놈
- 유물(artifact)과 가짜 상관관계(spurious correlations)
- 견고함을 향하여..
- 겨울철 논문 읽기 전 준비운동은 필수입니다!
- References
인삿말
안녕하세요!
NLP센터 금융언어이해팀 민중현 입니다.
NLP Tech 블로그를 통해 이야기 나눌 수 있어서 기쁘네요.
저는 표, 그래프 등 정형 데이터와 달리 문장, 문단 등 구조가 명확하지 않은 글로 이루어진 비정형 데이터에서 구조화된 정보 또는 지식을 추출하는 정보 추출을 연구/개발하고 있습니다. FOMC 회의록 또는 경제분야 뉴스 기사 등 금융 지식, 개체들 간의 관계, 또는 사건(이벤트)들을 서술, 논의하는 글로 이루어진 비정형 데이터를 주로 다루고 있어요. 이렇게 추출된 관계나 이벤트는 모아서 지식 베이스나 지식 그래프를 만들 수도 있고, 연속성 있는 이벤트들을 모아 인과관계를 파악할 수도 있으며, 클러스터링을 통해 서로 관련 있는 이벤트나 개체들을 한 눈에 볼 수도 있지요.
저는 학부 때 물리학을 전공했는데, 천체나 입자의 상호작용이 우주 속에서 어떤 체계를 가지고 나타나는지 연구 하는 것과 여러 개체들의 상호작용(관계, 이벤트 등)이 글 속에서 어떻게 구조화되어 나타나는지 연구 하는 게 비슷하다고 생각해 정보 추출이 더 매력적으로 느껴지더라고요. 이런 매력적인 일에도 물론 어려운 점이 여럿 있는데요, 그 중 하나가 오늘 이야기 나눌 견고함(robustness) 입니다.
 시작합니다! ㄱㄱㄱ: 견고함으로 가는 길!
(RRR 재미있어요! 인도영화 좋아하시면 추천해요)
시작합니다! ㄱㄱㄱ: 견고함으로 가는 길!
(RRR 재미있어요! 인도영화 좋아하시면 추천해요)
견고함(robustness)이 도대체 뭐야?
일반적인 의미의 견고함은 사물에 쓰일 경우, 모양이 쉽게 변하거나 부서지지 않을만큼 단단하고 튼튼하다는 의미를 가지며, 의지나 생각에 쓰일 경우에는 동요되지 않을만큼 매우 확고하다는 의미를 가진다고 하네요1. 이와 연관지어서, 언어 인공지능이 견고하다 할 때는, 해당 인공지능의 외부 분포 일반화(out-of-distribution generalization) 능력이 뛰어나, 전에 학습하지 못한 유형이나 형태의 입력에 대해서도 우수한 성능을 보인다고 이해 하면 되겠습니다. 새로운 환경, 정보, 또는 과제 앞에서 무너지지 않는 모습을 견고하다고 칭하는 비유적 표현인 것이죠.
좀 더 쉽게 알 수 있게 비유를 들어 보죠. 요즘 인기 절정이신 챗GPT 선생님께 여쭤봤어요.
“재료를 무엇이든 사용해 맛있는 요리를 만들 수 있는 요리사를 상상해보세요. 만약 요리사가 특정 재료와 요리법만 알고 있다면, 다른 재료와 상황에서 요리할 때 도움이 되지 않을 것입니다. 그러나 어떤 재료를 사용하더라도 맛있는 요리를 만들 수 있는 유연한 요리사는 매우 가치가 있습니다. 마찬가지로, 견고한 자연어 처리 시스템은 다양한 유형의 입력 데이터를 다룰 수 있고, 여전히 정확하고 의미 있는 출력을 제공할 수 있는 유연한 시스템입니다.”
 나쁘지 않군요. 고마워요, 챗GPT!
이력서를 다듬어야 하나..
나쁘지 않군요. 고마워요, 챗GPT!
이력서를 다듬어야 하나..
나쁘지 않군요. 좋은 예시란 많아도 많아도 부족하기에, 한가지 예를 더 들자면 아래 사진의 헤드 분리형 드라이버와 일체형 일자 드라이버가 될 수도 있겠네요. 분리형 드라이버와 같이 여러 분야의 과제나 환경에서 효과적인 도구가 있는 반면에, 단 하나의 환경에서만 효과적인(십자 나사 앞에서 쓸모 없는) 일자 드라이버 같은 도구도 있는 셈이죠!

 견고한 분리형 드라이버 와 견고하지 못한 일자 드라이버
견고한 분리형 드라이버 와 견고하지 못한 일자 드라이버
그렇다면 요즘 핫한 챗GPT를 비롯한 여러 딥러닝 인공지능은 견고할까요? 간단한 추론 능력을 요구하는 NLI (Natural Langauge Inference)라는 과제를 실행하는 여러 언어 인공지능을 살펴 보도록 해요. NLI는 전제(premise)와 가설(hypothesis)로 이루어진 하나의 문장 쌍(sentence pair)이 주어지고, 전제를 가정 했을 때, 가설이 사실인지 여부를 판단하는 과제입니다. 가설이 사실일 때 entailment (수반성)이 있다고 하고 가설이 사실이 아닐 때나 확실한 정보가 없을 때는 non-entailment (수반성 없음)라고 해요. 이 과제는 인공지능의 언어적 능력 뿐만 아니라 추론 능력과 공간 지각 능력 등 여러 인간적인(human-like)능력을 요구하기 때문에 인공지능의 발전을 평가할 때 중요한 척도로 사용되는 과제 중 하나예요. NLI의 예시를 조금 볼까요? 제가 주인공인 NLI 데이터셋을 하나 만들어 보죠!
| 전제 | 가설 | Entailment | 설명 | |
|---|---|---|---|---|
| 1 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 피곤하지 않아요. | 있음 | |
| 2 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 잠을 잘 잤어요. | 없음 | 중현이는 어제 잠을 잘 못 잤기 때문에, 수반성이 없어요. |
| 3 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 인간이예요. | 없음 | 전제만으로는 중현이가 인간인지, 다른 무언가인지 알 수 없어요. |
중현-NLI 데이터셋, 줄여서 JNLI를 소개합니다.
크지 않아도 되니 이 정도면 되겠네요. 데이터셋 이름도 붙여 봐요. 제 이름을 딴 중현-NLI, JNLI로 해요. 좋습니다! 이제 이 JNLI 데이터셋으로 견고한 인공지능과 그렇지 않은 인공지능은 NLI 에서 어떤 차이를 보일지 얘기해 봐요.
견고한 놈, 견고하지 않은 놈
자! 여기 인공지능이 둘 있어요. 넵구리와 몽구리 입니다!
 넵구리
넵구리
 몽구리
몽구리
(소곤소곤) 눈치 채셨나요? 넵구리는 견고한 인공지능, 몽구리는 견고하지 못한 인공지능입니다. 넵구리와 몽구리에게 JNLI를 사용해서 NLI 과제를 가르쳐 볼까요?
| 전제 | 가설 | Entailment | 넵구리의 생각 | 몽구리의 생각 | |
|---|---|---|---|---|---|
| 1 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 피곤하지 않아요. | 있음 | 중현이는 피곤하지 않았다는 전제가 있고, 가설은 그걸 그냥 반복해서 entailment가 있는 예시이구나. | 전제에 나오는 “중현”, “피곤” 등 주요 단어들이 그대로 가설에도 존재(어휘 중복)하면 entailment 구나! |
| 2 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 잠을 잘 잤어요. | 없음 | 전제와 가설이 반대되는 내용을 담고 있어 정답이 non-entailment 구나. | “잠”이라는 단어가 들어가면 정답이 non-entailment 이구나! |
| 3 | 중현이는 어제 잠을 잘 못 잤지만, 피곤하지는 않다고 하네요. | 중현이는 인간이예요. | 없음 | 중현이가 인간인지에 대한 내용은 전제에 없어서 non-entailment 구나. | “인간”이라는 단어가 들어가면 정답이 non-entailment 이구나! |
넵구리는 NLI는 전제와 가설 사이의 관계를 이용해 추론능력을 바탕으로 풀어야 하는 과제라는 걸 잘 이해한 반면, 몽구리는 그렇지 못한 채, 잘못된 정보에 집중을 하게 됐어요. 넵구리와 몽구리 모두 이미 본 적 있는 JNLI (내부 분포: in-distribution)에서는 만점을 받을 수 있겠지요! 그런데, 다른 단어들로 이루어져 있거나, 주제가 다른 데이터셋(외부 분포: out-of-distribution)에서는 그 차이가 두드러질 수 밖에 없습니다. 이런 이유로 견고한 인공지능은 다양한 데이터셋과 과제, 그리고 분야에 우수한 성능을 보이지만, 견고하지 못한 인공지능은 그럴 수 없죠. 분리형 드라이버와 일자형 드라이버 처럼요.
JNLI 에는 어휘 중복, “잠”이라는 단어의 존재, “인간”이라는 단어의 존재와 수반성 사이에 상관 관계가 있는 데이터셋이예요. 이렇게 의도되지는 않았지만, 어쨌거나 데이터셋 내에 존재하는 정보를 artifact (유물)라고 해요. 견고한 넵구리는 artifact에 영향을 받지 않았지만, 몽구리는 우연의 일치로 만들어진 단어 분포나 어휘 중복을 entailment 여부에 연결하는 잘못된 결론을 내렸어요. 이를 두고 가짜 상관관계(spurious correlation)를 학습했다고 할 수 있어요.
유물(artifact)과 가짜 상관관계(spurious correlations)
JNLI의 artifact 몇가지와 이로 인해 견고하지 못한 인공지능이 배우게 되는 가짜 상관관계를 소개 드렸는데요, 사실
이
모든 것은
실화입니다.
MultiNLI2이라는 약 50만개의 문장 쌍과 그에 대한 정답(레이블: label)으로 구성된 NLI 데이터셋이 있어요. 줄여서 MNLI라고 쓸게요. 견고함이 인공지능 분야의 본격적인 화두로 떠오르기 전, MNLI 에 대한 최신 인공지능의 성적은 100점 만점에 90점 정도를 기록했는데요, 이는 90점을 약간 넘긴 인간 성능과 맞먹는 수준이었기 때문에 인공지능에 대한 기대치가 하늘을 찌를 때 였어요. 그런데, MNLI와 이를 학습한 인공지능에 대해 흥미로운 연구결과가 제시되기 시작해요.
Sleeping (잠), humans (인간)과 같은 일반 동/명사가 정답 레이블 중 하나인 entailment 레이블과 큰 상관관계를 보여 전제 없이 가설만 보고도 어느 정도 고득점이 가능하다는 연구3, 어휘 중복(lexical overlap)을 수반성과 연결 시키는 경향이 있다는 연구4, MNLI 로 학습한 인공지능 100개를 HANS4라는 다른 NLI 데이터셋에 평가했더니 무려 100점 만점에 평균 57점 밖에 받지 못했다는 연구5..
 선택지 2개면..다 찍어도 50점 인데..?
선택지 2개면..다 찍어도 50점 인데..?
우리 똑똑한 인공지능들이 넵구리 인줄 알았는데, 사실은 내부 분포에서 아무리 고득점을 받아도 외부 분포로의 일반화 능력은 거의 없다시피 한 몽구리였다고..?
충격과 공포였어요!
안타깝게도 이 문제는 지금까지도 지속되는데요, 어휘 중복과 entailment 사이의 가짜 상관관계는 원 글 작성 당시 OpenAI의 ChatGPT 에서도 나타나는 문제 중 하나입니다.
 천하의 ChatGPT가..! 제 직업은 (지금으로선) 안전합니다 (웃음)
정답은 non-entailment 입니다. 춤을 춘 사람은 의사이지, 배우가 아니죠.
천하의 ChatGPT가..! 제 직업은 (지금으로선) 안전합니다 (웃음)
정답은 non-entailment 입니다. 춤을 춘 사람은 의사이지, 배우가 아니죠.
견고함을 향하여..
더 견고한 인공지능을 만들기 위해서는 어떻게 해야할까요?
이런 가짜 상관 관계를 줄여야 하는데요, 그러기 위해서는 학습 데이터셋의 artifact을 줄이거나, 인공지능 자체의 언어/일반화 능력을 더 향상시켜 artifact에서 학습되는 가짜 상관 관계를 줄이는 방법이 있겠지요. 비교적 최근까지는 전자가 더 많이 시도되었어요.
Artifact을 줄이려면 어떻게 해야 할까요? 연구자들이 artifact를 확인 한 후, 해당 artifact 에 대한 반례를 추가하는 방법이 가장 먼저 떠오르네요. 예시를 하나 보여 드릴게요. Min et al. (ACL 2020)6에서 발췌한 예시입니다. 어휘 중복과 수반성 사이의 가짜 상관 관계를 줄이는 것을 목표로 한 데이터 증강(데이터를 추가해서 인공지능의 성능을 높이는 것)입니다.
Min et al. (2020)6의 연구자들은 어휘 중복과 entailment 레이블 사이의 가짜 상관 관계를 줄이기 위해, 어휘 중복이 있으면서 entailment는 없는 문장쌍을 만들었어요. 생각나는 대로 아무 단어나 골라서 만들 수 도 있지만, 원활한 학습을 위해 어휘 분포를 보존하려고 MNLI 내에서 주어-동사-목적어 순서로 된 간단한 문장들을 찾았지요. 이를테면 “Junghyun is a human” (중현이는 인간이예요) 같이요. 이렇게 찾은 1,205개의 문장들의 주어와 목적어를 바꿉니다! (A human is Junghyun) 그런 뒤, 새로운 문장쌍을 만들어요. 전제는 바뀌기 전의 문장, 가설은 바뀐 후의 문장입니다. 이렇게요!
원래 문장쌍: 중현이는 인간이고, 어제 잠을 잘 못 잤어요. → 중현이는 인간이예요. (수반성 있음)
데이터 증강을 위해 새로 만든 문장쌍: 중현이는 인간이예요. ↛ 인간은 중현이예요. (수반성 없음)
데이터 증강을 위해 새로 만든 문장쌍은 어휘 중복은 있지만(전제와 가설이 같은 어휘로 구성되어 있지만), entailment는 없어요. 이런 식으로 어휘 중복이 있으면서 수반하지 않는 문장쌍을 만들어서, artifact의 흔적을 줄여, 궁극적으로 인공지능이 학습할 가짜 상관 관계를 줄여 나가는 방법을 제안하는 논문이죠. 간단한 데이터 조정 및 증강으로 견고함에 한 발자국 다가갈 수 있게 하는, 쉽지만 효과적인 방법으로 볼 수 있습니다. 에헴!
 필자는 이 Min et al. 20206 논문을 좋아합니다. 왜 인지는 비밀입니다!
필자는 이 Min et al. 20206 논문을 좋아합니다. 왜 인지는 비밀입니다!
아무튼, 이렇게 인간이 현상을 관찰하고 판단하여 데이터 증강이나 모델 구조 개선 등을 통해 직접 개입하는 방법을 휴먼 인 더 루프(human-in-the-loop) 접근이라고 해요. 이런 방법은 효과적이지만, 인간의 판단을 필요로 하기에 시간적, 노동적 비용이 크다는 단점이 있죠. 오늘 소개할 논문은 인간의 개입 없이도 더 견고한 인공지능을 학습할 수 있는 방법론을 한 가지 제안합니다.
상세하게 설명하기 전에 먼저 몇가지 용어를 정의하고 넘어가도록 해요.
겨울철 논문 읽기 전 준비운동은 필수입니다!
- 표현(representation)
- 단어, 문장, 문장쌍 등을 벡터 또는 텐서로 변환한 결과물. 수십-수백 차원의 피처(feature)로 이루어져 있어요. NLI 와 같은 문장 분류 문제는 결국 이 표현 공간(representation space)과 레이블 공간(label space) 간의 매핑 문제예요. 비슷한 의미를 가진 문자열은 표현 공간에서 상대적으로 가깝다고 이해 할 수 있죠.
- 피처(feature)
- 단어, 문장, 문단 내의 유의미한 특징을 나타내며, 단어의 출현 빈도나 문장의 길이 등 인간이 이해할 수 있는 피처도 있지만, 해당 문자열 내 단어 분포의 역 로그우도(inverse log likelihood) 등 쉽게 인간이 이해 할 수 없는 피처도 있을 수 있어요. 기계학습으로 생성된 피처들은 대게 표준화 되어 -1 과 1 사이의 값을 가져요.
- 인코더(encoder)
- 입력된 단어, 문장, 문단 등 문자열을 표현(representation)으로 변환하는 함수예요. 기계학습 에서는 실제 물리적 매핑의 모형을 구현 하는 것이 목적이므로 “모델”이라 칭하기도 한답니다.
- 분류기(classifier)
- 표현을 레이블로 분류하는 함수예요. 기계학습 에서는 실제 물리적 매핑의 모형을 구현 하는 것이 목적이므로 “모델”이라 칭하기도 하죠.
- 손실(loss)
- 모델의 예측(예측된 레이블: predicted label)과 실제 값의 차이를 측정하는 지표를 의미해요. 인코더와 분류기를 학습 할 때, 이 손실을 최소화 하는 방향으로 해당 함수의 계수(모델의 파라미터)가 업데이트 돼요.
음. 문제가 생겼습니다. 말투만 나긋나긋하고 내용은 벽돌처럼 딱딱하다는 피드백을 받았어요. 황급히 파워포인트를 열어서 제 그림 실력을 뽐낼 시간이군요!
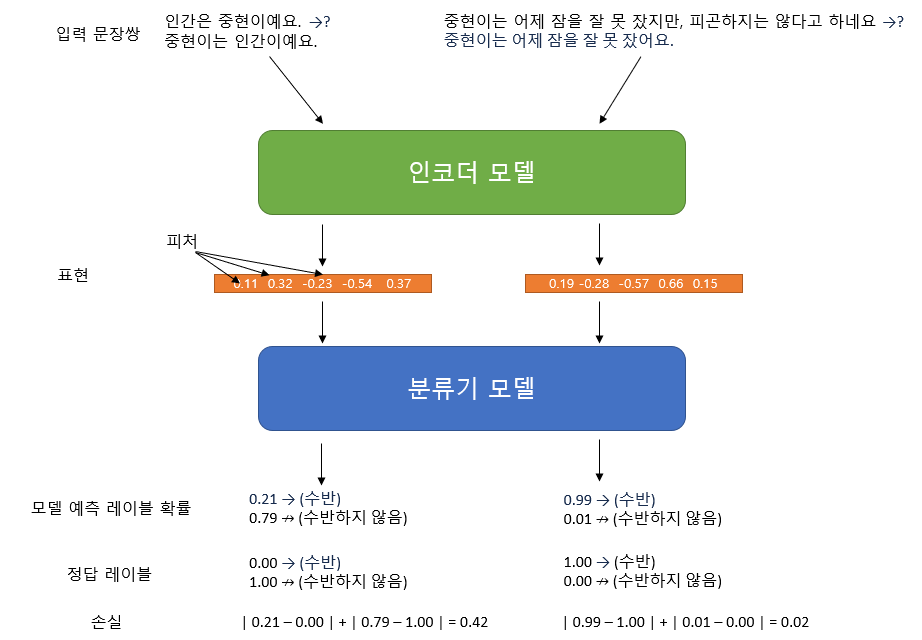 NLI 모델의 구조 (디자이너 급구!)
NLI 모델의 구조 (디자이너 급구!)
이제 좀 나아졌군요. 그림이 도움이 되었으면 좋겠는데, 모델의 구조가 이해 되시나요?
준비운동을 모두 마쳤네요! 이제 논문으로 가 볼까요?

(ㄱㄱㄱ 2편에서 이어집니다)
References
-
네이버 고려대한국어대사전, Last access Feb 22, 2023 ↩
-
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference (Williams et al., NAACL 2018) ↩
-
Hypothesis Only Baselines in Natural Language Inference (Poliak et al., SemEval 2018) ↩
-
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (McCoy et al., ACL 2019) ↩ ↩2
-
BERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance (McCoy, Min, and Linzen, BlackboxNLP 2020) ↩
-
Syntactic Data Augmentation Increases Robustness to Inference Heuristics (Min et al., ACL 2020) ↩ ↩2 ↩3
